皆さんこんにちは。
業務ハックLabのよ~よんです。
私が参加しているMicrosoft MVPの前田さんが運営しているコミュニティ「おうじゃさんといっしょ」で安否確認システムのハンズオンをすることになったので予習、復習ができるように先日挙げた内容の詳細を書いていこうと思います。
がっつり書くとハンズオンにならないかもしれないですけどこのボリュームを当日に説明しきるのは無理!ってことでご容赦ください(笑)
概要
概要部分は前回の記事を参照してもらえば書いているのでそちらをどーぞ!
ちなみにこれは大事なので今回も書いておきます。
Power AutomateはPremiumコネクタであるHTTPコネクタを使用するので有料版のライセンス(Micosoft365付属のライセンスは不可)が必要になりますのでご注意ください。
全体の流れとしてはこんな感じ。

ハンズオンでは気象庁のホームページからxml情報を取得する方法を案内します。
気象庁の情報取得ページはこちら
注意事項
これは前回も書いたのですが大事なことなので今回も書いておきます。
下記についてご注意願います。
- 今回作成したこの安否確認システムでは気象庁ホームページから情報を入手しています。使用に際しては気象庁の情報を利用している旨の表示が必要となります。気象庁 | 著作権・リンク・個人情報保護について
- あくまで個人的に作成したものですので無保証です。利用によるいかなる損害についても、一切の責任を負いません。
また、情報の正確性も一切保証致しません。
ちなみにむやみに高頻度でアクセスをすると気象庁のサーバーに負荷がかかってしまう為、設定は気を付けるようにしてくださいね。
前回実行を判定する為のExcel作成
自分のOneDrive上に下記のような形で判定用のExcelを作成します。

テーブル形式にして「key」「前回スクリプト実行時間」「ID」の3列を作成し、
key列に「1」とだけ入力しておきます。
前回スクリプト実行時間の書式は上の画像の通りに、IDの書式は「文字列」にしておきましょう。
上の画像は実行時間とIDに値が入っているけど作ったときは空白でOK。
Power Automateの構成
前回は大まかな説明のみとしましたが今回は少し詳しく書いていきます。
気象庁ホームページxml情報取得パターン
色々とフィルタを掛けたりしてるので結構長いフローに見えますが変数をいっぱい使っているので実際はそんなでもないです。
全体を見るとこんな感じ。
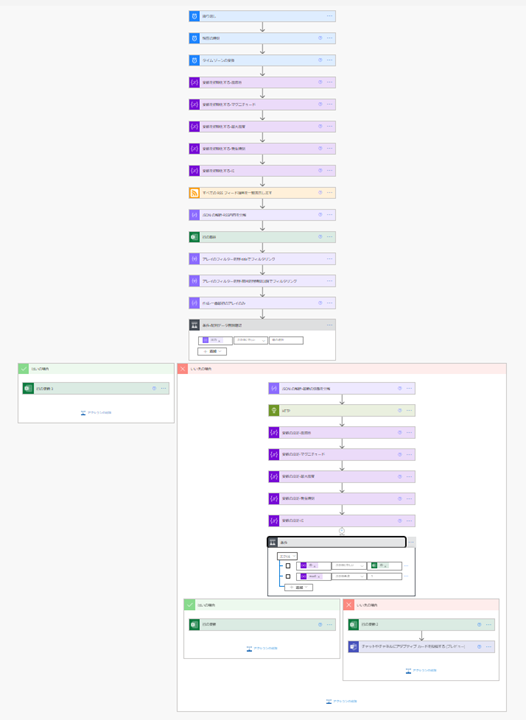
分解しつつ、動きの部分の詳細を説明していきます。
トリガー~タイムゾーンの変換
この安否確認システムでは気象庁から地震速報を受信する形ではなく、気象庁HPへ地震速報がないか情報を取りに行く形のものになっています。
ですのでトリガーを「繰り返し」にして定期的に情報を取りに行くようにします。
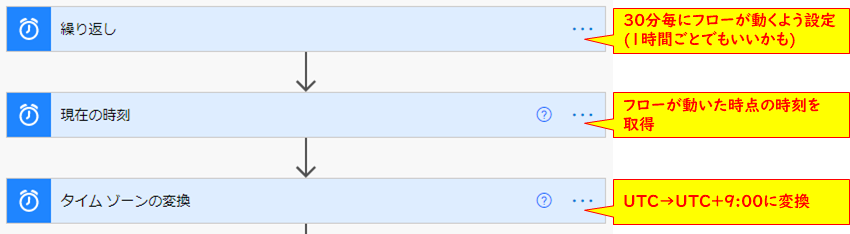
トリガー【繰り返し】
| 設定名 | 設定値 |
| 間隔 | 30 |
| 頻度 | 分 |
※気象庁のサーバーやAPIコール数も考慮して設定しましょう。
コネクタ【現在の時刻】
このコネクタを利用して現在時刻を取得します。(設定項目なし)
コネクタ【タイムゾーンの変換】
| 設定名 | 設定値 |
| 基準時間 | 現在の時刻 |
| 書式設定文字列 | 世界共通並べ替え可能な日時パターン |
| 変換元のタイムゾーン | (UTC)協定世界時 |
| 変換先のタイムゾーン | (UTC+09:00)大阪、札幌、東京 |
変数の定義
ここでは後工程で使う変数を定義します。
コネクタを置くだけなので特に詳細な説明はありません。
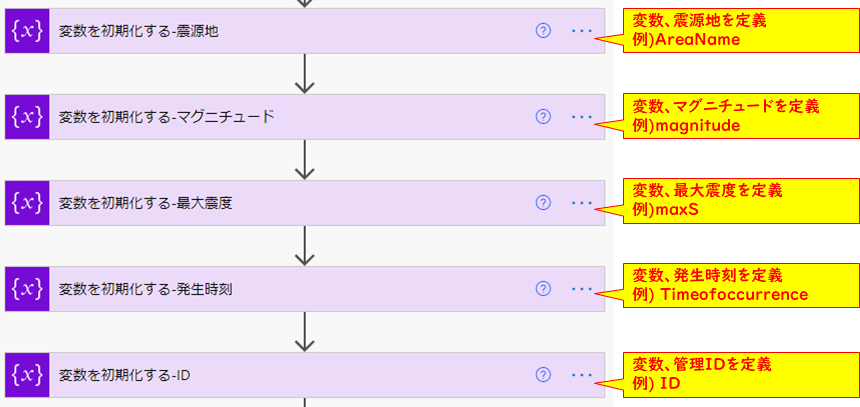
フィードの取得~作成-一番最初のアレイのみ
RSSコネクタで気象庁のホームページからフィード項目を取得しています。
ちなみに今回はAtomフィードの高頻度、「地震火山」の情報を使用しています。
流れとしてはコネクタでAtomフィードを取得し、そのデータをJSONの解析で後工程で利用できるよう分解、その後、必要な情報のみ取得するようフィルタリングをかけます。

コネクタ【すべてのRSSフィード項目を一覧表示します】
| 設定名 | 設定値 |
| RSSフィードのURL | http://www.data.jma.go.jp/developer/xml/feed/eqvol.xml |
| 以降 | 本日の日時以降の値 例)2021-03-22 10:00:00Z |
| 選択したプロパティを・・・ | PublishDate |
| 設定名 | 設定値 |
| コンテンツ | RSSのbody |
| スキーマ | 下記参照 |
コネクタ【行の取得】
| 設定名 | 設定値 |
| 場所 | OneDrive for Business |
| ドキュメントライブラリ | OneDrive |
| ファイル | 前段で作成したファイルを指定 |
| テーブル | テーブルを指定 例)テーブル1 |
| キー列 | キー列を指定する 例)key |
| キー値 | 1 |
コネクタ【アレイのフィルター処理-titleでフィルタリング】
| 設定名 | 設定値 |
| 差出人 | JSONの解析-RSS内容を分解の本文 |
| フィルタ対象 | 前項のJSONの解析で分解したtitle |
| 条件 | 次の値に等しい |
| フィルタ条件 | 震源・震度に関する情報 |
コネクタ【アレイのフィルター処理-前回処理時間以降でフィルタリング】
| 設定名 | 設定値 |
| 差出人 | アレイのフィルター処理-titleでフィルタリングの本文 |
| フィルタ対象 | 前項のアレイのフィルター処理-titleでフィルタリングしたupdatedOn |
| 条件 | 次の値より大きい |
| フィルタ条件 | Excelaの前回スクリプト実行時間 |
コネクタ【作成-一番最初のアレイのみ】
| 設定名 | 設定値 |
| 入力 | first(body('アレイのフィルター処理-前回処理時間以降でフィルタリング')) |
条件分岐
フィードからデータを取得した際に様々な条件でフィルタを掛けますが条件に合致せず、データが空白だった場合に分岐するよう設定をします。
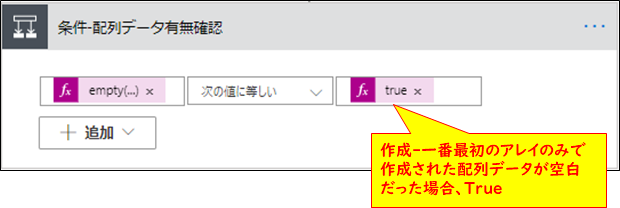
コネクタ【条件-配列データ有無確認】
| 対象 | 条件 | 条件の値 |
| empty(outputs('作成-一番最初のアレイのみ')) | 次の値に等しい | true |
はいの場合
上記の条件に合致する(データが空白)場合は最新情報がない状態なので処理時間のみをExcelデータに更新してフローを終了します。
コネクタ【行の更新】
| 設定名 | 設定値 |
| 場所 | OneDrive for Business |
| ドキュメントライブラリ | OneDrive |
| ファイル | 前段で作成したファイルを指定 |
| テーブル | テーブルを指定 例)テーブル1 |
| キー列 | キー列を指定する 例)key |
| キー値 | 1 |
| key | 1 |
| 前回スクリプト実行時間 | 変換後の時間 |
| ID | 空白 |
いいえの場合:JSONの解析-最新情報を分解~条件分岐
上記条件に合致しない(データが空白ではない)場合は最新情報がある状態ですので次の工程に進みます。
具体的には取得した情報の中に地震情報の詳細が記載されたxmlデータへのURLが存在するので、そのデータをHTTPコネクタでGETしています。
また最後に条件アクションですでに取得済みの管理ID(取得したデータが同一の地震情報なのかの判定)、安否確認を投稿する最大震度の下限値を設定します。

コネクタ【JSON の解析-最新の情報を分解】
| 設定名 | 設定値 |
| コンテンツ | 「作成」の出力 |
| スキーマ | 下記参照 |
コネクタ【HTTP】
| 設定名 | 設定値 |
| 方法 | GET |
| URI | 「JSON の解析-最新の情報を分解」のprimaryLink |
コネクタ【変数の設定-震源地】
| 設定名 | 設定値 |
| 名前 | 変数の初期化で設定した変数名 |
| 値 | xpath(xml(body('HTTP')), 'string(/*[name()="jmx:Report"]/*[name()="Body"]/*[name()="Earthquake"]/*[name()="Hypocenter"]/*[name()="Area"]/*[name()="Name"])') |
コネクタ【変数の設定-マグニチュード】
| 設定名 | 設定値 |
| 名前 | 変数の初期化で設定した変数名 |
| 値 | xpath(xml(body('HTTP')), 'string(/*[name()="jmx:Report"]/*[name()="Body"]/*[name()="Earthquake"]/*[name()="jmx_eb:Magnitude"])') |
コネクタ【変数の設定-最大震度】
| 設定名 | 設定値 |
| 名前 | 変数の初期化で設定した変数名 |
| 値 | xpath(xml(body('HTTP')), 'string(/*[name()="jmx:Report"]/*[name()="Body"]/*[name()="Intensity"]/*[name()="Observation"]/*[name()="MaxInt"])') |
コネクタ【変数の設定-発生時刻】
| 設定名 | 設定値 |
| 名前 | 変数の初期化で設定した変数名 |
| 値 | xpath(xml(body('HTTP')), 'string(/*[name()="jmx:Report"]/*[name()="Body"]/*[name()="Earthquake"]/*[name()="OriginTime"])') |
コネクタ【変数の設定-ID】
| 設定名 | 設定値 |
| 名前 | 変数の初期化で設定した変数名 |
| 値 | xpath(xml(body('HTTP')), 'string(/*[name()="jmx:Report"]/*[name()="Head"]/*[name()="EventID"])') |
条件アクションの中はこのような感じになっています。
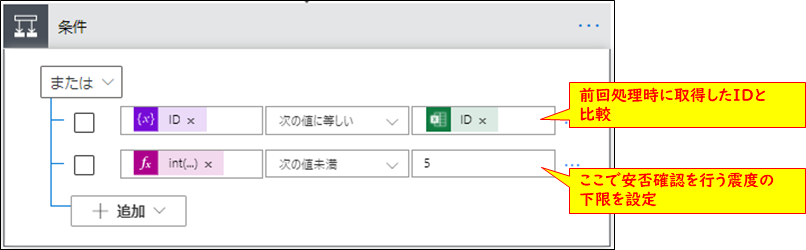
コネクタ【条件】
条件は二つでイベントIDと震度で条件指定をします。「AND」ではなく「OR(または)」で条件を指定します。
| 対象 | 条件 | 条件の値 |
| 「変数」のID | 次の値に等しい | ExcelのID |
| if(greater(5,int(substring(variables('maxS'),0,1))),true,false) | 次の値未満 | true |
はいの場合
上記の条件に合致する(すでに取得、投稿済みのデータもしくは最大震度しきい値未満の地震)場合は最新情報がない状態なので処理時間のみをExcelデータに更新してフローを終了します。
ここは前項でも同じ処理をしているのでそちらを参照してください。

いいえの場合:行の更新~アダプティブカード投稿
上記条件に合致しない(まだ投稿していない情報かつ最大震度しきい値以上)場合は最新情報がある状態ですので次の工程に進みます。
Excelデータへ処理日時と管理IDを更新しAdaptive cardsを特定のチャネルへ投稿します。

コネクタ【行の更新】
| 設定名 | 設定値 |
| 場所 | OneDrive for Business |
| ドキュメントライブラリ | OneDrive |
| ファイル | 前段で作成したファイルを指定 |
| テーブル | テーブルを指定 例)テーブル1 |
| キー列 | キー列を指定する 例)key |
| キー値 | 1 |
| key | 1 |
| 前回スクリプト実行時間 | 変換後の時間 |
| ID | 「変数」のID |
コネクタ【チャットやチャネルにアダプティブ カードを投稿する】
| 設定名 | 設定値 |
| 投稿者 | Flow bot |
| 投稿先 | Channel |
| Team | 投稿したいチームを指定 |
| Channel | 投稿したいチャネルを指定 |
| AdaptiveCard | 下記参照 |
気象庁ホームページxml情報取得するフローの詳細説明は以上です。
因みにPower BIのストリーミングデータセットへのデータ格納方法などについては前回の記事にそれなりに詳しく記載してありますので今回の記事では割愛します。
xpathやらJSONの解析やら訳の分からないことが結構あると思いますがそれぞれ自分で試行錯誤しながら作ると理解ができるようになってきます。
私もxpathの部分はかなり嵌りました・・・
でも理解できるようになると一つレベルアップしたと実感できるので皆さん大いに苦労しましょう(笑)
苦労しただけ嬉しさもひとしおなので!
それでは本日はこのへんで!
皆さん良い業務ハックライフを~
![]()